For function calls, register saves go via stack (to allow nested saves) for simpler cases, registers are saved in a local variable. Fixed too agressive removal of sta-lda sequence if the lda is followed by a branching instruction. Insert missing cmp #0 after functioncall if the value of the A register is needed in a comparison expression (could otherwise test wrong status flag) |
||
|---|---|---|
| .idea | ||
| compiler | ||
| docs | ||
| examples | ||
| gradle/wrapper | ||
| parser | ||
| scripts | ||
| syntax-files | ||
| .gitignore | ||
| .travis.yml | ||
| gradle.properties | ||
| gradlew | ||
| gradlew.bat | ||
| LICENSE | ||
| README.md | ||
| settings.gradle | ||
![]()

Prog8 - Structured Programming Language for 8-bit 6502/65c02 microprocessors
Written by Irmen de Jong (irmen@razorvine.net)
Software license: GNU GPL 3.0, see file LICENSE
This is a structured programming language for the 8-bit 6502/6510/65c02 microprocessor from the late 1970's and 1980's as used in many home computers from that era. It is a medium to low level programming language, which aims to provide many conveniences over raw assembly code (even when using a macro assembler).
Documentation
Full documentation (syntax reference, how to use the language and the compiler, etc.) can be found at: https://prog8.readthedocs.io/
What does Prog8 provide?
- big reduction of source code length over raw assembly
- modularity, symbol scoping, subroutines
- various data types other than just bytes (16-bit words, floats, strings)
- automatic variable allocations, automatic string and array variables and string sharing
- subroutines with an input- and output parameter signature
- no stack frame allocations because parameters and local variables are automatically allocated statically
- constant folding in expressions and other high-level program optimizations
- conditional branches
- floating point operations (requires the C64 Basic ROM routines for this)
- 'when' statement to provide a concise jump table alternative to if/elseif chains
- many built-in functions such as
sin,cos,rnd,abs,min,max,sqrt,msb,rol,ror,swap,memset,memcopy,sortandreverse - structs to group together sets of variables and manipulate them at once
- convenience abstractions for low level aspects such as ZeroPage handling, program startup, explicit memory addresses
- fast execution speed due to compilation to native assembly code
- inline assembly allows you to have full control when every cycle or byte matters
Rapid edit-compile-run-debug cycle:
- use a modern PC to do the work on, use nice editors and enjoy quick compilation times
- can automatically run the program in the Vice emulator after succesful compilation
- breakpoints, that let the Vice emulator drop into the monitor if execution hits them
- source code labels automatically loaded in Vice emulator so it can show them in disassembly
Two supported compiler targets (contributions to improve these or to add support for other machines are welcome!):
- "c64": Commodore-64 (6510 CPU = almost a 6502), the main target.
- "cx16": CommanderX16 (65c02 CPU) .
- If you only use standard kernel and prog8 library routines, it is possible to compile the exact same program for both machines (just change the compiler target flag)!
Additional required tools
64tass - cross assembler. Install this on your shell path. A recent .exe version of this tool for Windows can be obtained from my clone of this project. For other platforms it is very easy to compile it yourself (make ; make install).
A Java runtime (jre or jdk), version 11 or newer is required to run a prepackaged version of the compiler. If you want to build it from source, you'll need a Java SDK + Kotlin 1.3.x SDK (or for instance, IntelliJ IDEA with the Kotlin plugin).
It's handy to have an emulator (or a real machine perhaps!) to run the programs on. The compiler assumes the presence of the Vice emulator for the C64 target, and the x16emu emulator for the CommanderX16 target.
Example code
This code calculates prime numbers using the Sieve of Eratosthenes algorithm::
%import textio
%zeropage basicsafe
main {
ubyte[256] sieve
ubyte candidate_prime = 2 ; is increased in the loop
sub start() {
; clear the sieve, to reset starting situation on subsequent runs
memset(sieve, 256, false)
; calculate primes
txt.print("prime numbers up to 255:\n\n")
ubyte amount=0
repeat {
ubyte prime = find_next_prime()
if prime==0
break
txt.print_ub(prime)
txt.print(", ")
amount++
}
txt.chrout('\n')
txt.print("number of primes (expected 54): ")
txt.print_ub(amount)
txt.chrout('\n')
}
sub find_next_prime() -> ubyte {
while sieve[candidate_prime] {
candidate_prime++
if candidate_prime==0
return 0 ; we wrapped; no more primes available in the sieve
}
; found next one, mark the multiples and return it.
sieve[candidate_prime] = true
uword multiple = candidate_prime
while multiple < len(sieve) {
sieve[lsb(multiple)] = true
multiple += candidate_prime
}
return candidate_prime
}
}
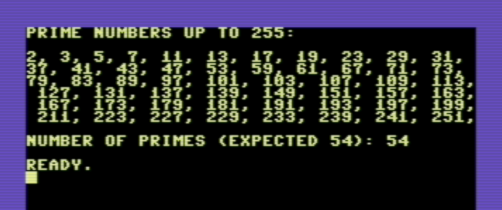
when compiled an ran on a C-64 you'll get:
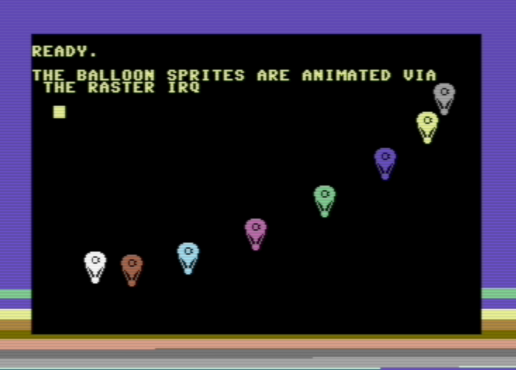
One of the included examples (wizzine.p8) animates a bunch of sprite balloons and looks like this:
Another example (cube3d-sprites.p8) draws the vertices of a rotating 3d cube:

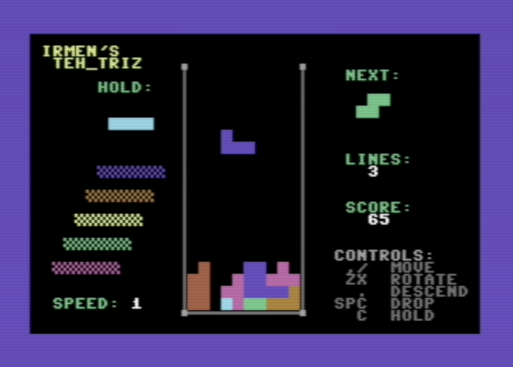
If you want to play a video game, a fully working Tetris clone is included in the examples:
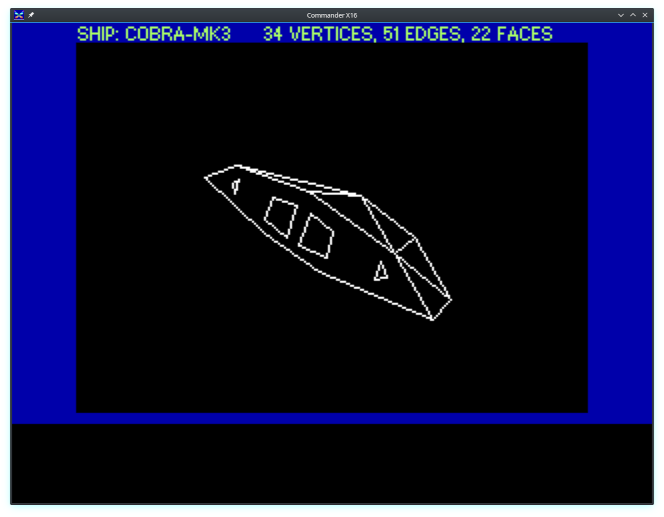
The CommanderX16 compiler target is quite capable already too, here's a well known space ship animated in 3D with hidden line removal, in the CommanderX16 emulator: