Kaleidoscope: Extending the Language: Control Flow
Welcome to Chapter 5 of the "Implementing a language
with LLVM" tutorial. Parts 1-4 described the implementation of the simple
Kaleidoscope language and included support for generating LLVM IR, followed by
optimizations and a JIT compiler. Unfortunately, as presented, Kaleidoscope is
mostly useless: it has no control flow other than call and return. This means
that you can't have conditional branches in the code, significantly limiting its
power. In this episode of "build that compiler", we'll extend Kaleidoscope to
have an if/then/else expression plus a simple 'for' loop.
Extending Kaleidoscope to support if/then/else is quite straightforward. It
basically requires adding lexer support for this "new" concept to the lexer,
parser, AST, and LLVM code emitter. This example is nice, because it shows how
easy it is to "grow" a language over time, incrementally extending it as new
ideas are discovered.
Before we get going on "how" we add this extension, lets talk about "what" we
want. The basic idea is that we want to be able to write this sort of thing:
def fib(x)
if x < 3 then
1
else
fib(x-1)+fib(x-2);
In Kaleidoscope, every construct is an expression: there are no statements.
As such, the if/then/else expression needs to return a value like any other.
Since we're using a mostly functional form, we'll have it evaluate its
conditional, then return the 'then' or 'else' value based on how the condition
was resolved. This is very similar to the C "?:" expression.
The semantics of the if/then/else expression is that it evaluates the
condition to a boolean equality value: 0.0 is considered to be false and
everything else is considered to be true.
If the condition is true, the first subexpression is evaluated and returned, if
the condition is false, the second subexpression is evaluated and returned.
Since Kaleidoscope allows side-effects, this behavior is important to nail down.
Now that we know what we "want", lets break this down into its constituent
pieces.
The lexer extensions are straightforward. First we add new enum values
for the relevant tokens:
// control
tok_if = -6, tok_then = -7, tok_else = -8,
Once we have that, we recognize the new keywords in the lexer. This is pretty simple
stuff:
...
if (IdentifierStr == "def") return tok_def;
if (IdentifierStr == "extern") return tok_extern;
if (IdentifierStr == "if") return tok_if;
if (IdentifierStr == "then") return tok_then;
if (IdentifierStr == "else") return tok_else;
return tok_identifier;
To represent the new expression we add a new AST node for it:
/// IfExprAST - Expression class for if/then/else.
class IfExprAST : public ExprAST {
ExprAST *Cond, *Then, *Else;
public:
IfExprAST(ExprAST *cond, ExprAST *then, ExprAST *_else)
: Cond(cond), Then(then), Else(_else) {}
virtual Value *Codegen();
};
The AST node just has pointers to the various subexpressions.
Now that we have the relevant tokens coming from the lexer and we have the
AST node to build, our parsing logic is relatively straightforward. First we
define a new parsing function:
/// ifexpr ::= 'if' expression 'then' expression 'else' expression
static ExprAST *ParseIfExpr() {
getNextToken(); // eat the if.
// condition.
ExprAST *Cond = ParseExpression();
if (!Cond) return 0;
if (CurTok != tok_then)
return Error("expected then");
getNextToken(); // eat the then
ExprAST *Then = ParseExpression();
if (Then == 0) return 0;
if (CurTok != tok_else)
return Error("expected else");
getNextToken();
ExprAST *Else = ParseExpression();
if (!Else) return 0;
return new IfExprAST(Cond, Then, Else);
}
Next we hook it up as a primary expression:
static ExprAST *ParsePrimary() {
switch (CurTok) {
default: return Error("unknown token when expecting an expression");
case tok_identifier: return ParseIdentifierExpr();
case tok_number: return ParseNumberExpr();
case '(': return ParseParenExpr();
case tok_if: return ParseIfExpr();
}
}
Now that we have it parsing and building the AST, the final piece is adding
LLVM code generation support. This is the most interesting part of the
if/then/else example, because this is where it starts to introduce new concepts.
All of the code above has been thoroughly described in previous chapters.
To motivate the code we want to produce, lets take a look at a simple
example. Consider:
extern foo();
extern bar();
def baz(x) if x then foo() else bar();
If you disable optimizations, the code you'll (soon) get from Kaleidoscope
looks like this:
declare double @foo()
declare double @bar()
define double @baz(double %x) {
entry:
%ifcond = fcmp one double %x, 0.000000e+00
br i1 %ifcond, label %then, label %else
then: ; preds = %entry
%calltmp = call double @foo()
br label %ifcont
else: ; preds = %entry
%calltmp1 = call double @bar()
br label %ifcont
ifcont: ; preds = %else, %then
%iftmp = phi double [ %calltmp, %then ], [ %calltmp1, %else ]
ret double %iftmp
}
To visualize the control flow graph, you can use a nifty feature of the LLVM
'opt' tool. If you put this LLVM IR
into "t.ll" and run "llvm-as < t.ll | opt -analyze -view-cfg", a window will pop up and you'll
see this graph:
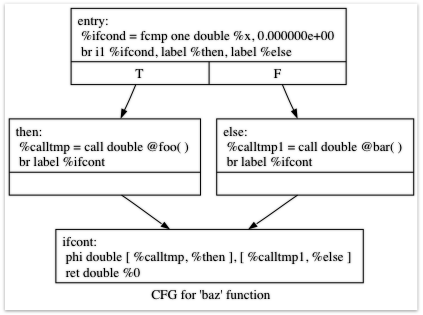
Another way to get this is to call "F->viewCFG()" or
"F->viewCFGOnly()" (where F is a "Function*") either by
inserting actual calls into the code and recompiling or by calling these in the
debugger. LLVM has many nice features for visualizing various graphs.
Getting back to the generated code, it is fairly simple: the entry block
evaluates the conditional expression ("x" in our case here) and compares the
result to 0.0 with the "fcmp one"
instruction ('one' is "Ordered and Not Equal"). Based on the result of this
expression, the code jumps to either the "then" or "else" blocks, which contain
the expressions for the true/false cases.
Once the then/else blocks are finished executing, they both branch back to the
'ifcont' block to execute the code that happens after the if/then/else. In this
case the only thing left to do is to return to the caller of the function. The
question then becomes: how does the code know which expression to return?
The answer to this question involves an important SSA operation: the
Phi
operation. If you're not familiar with SSA, the wikipedia
article is a good introduction and there are various other introductions to
it available on your favorite search engine. The short version is that
"execution" of the Phi operation requires "remembering" which block control came
from. The Phi operation takes on the value corresponding to the input control
block. In this case, if control comes in from the "then" block, it gets the
value of "calltmp". If control comes from the "else" block, it gets the value
of "calltmp1".
At this point, you are probably starting to think "Oh no! This means my
simple and elegant front-end will have to start generating SSA form in order to
use LLVM!". Fortunately, this is not the case, and we strongly advise
not implementing an SSA construction algorithm in your front-end
unless there is an amazingly good reason to do so. In practice, there are two
sorts of values that float around in code written for your average imperative
programming language that might need Phi nodes:
- Code that involves user variables: x = 1; x = x + 1;
- Values that are implicit in the structure of your AST, such as the Phi node
in this case.
In Chapter 7 of this tutorial ("mutable
variables"), we'll talk about #1
in depth. For now, just believe me that you don't need SSA construction to
handle this case. For #2, you have the choice of using the techniques that we will
describe for #1, or you can insert Phi nodes directly, if convenient. In this
case, it is really really easy to generate the Phi node, so we choose to do it
directly.
Okay, enough of the motivation and overview, lets generate code!
In order to generate code for this, we implement the Codegen method
for IfExprAST:
Value *IfExprAST::Codegen() {
Value *CondV = Cond->Codegen();
if (CondV == 0) return 0;
// Convert condition to a bool by comparing equal to 0.0.
CondV = Builder.CreateFCmpONE(CondV,
ConstantFP::get(Type::DoubleTy, APFloat(0.0)),
"ifcond");
This code is straightforward and similar to what we saw before. We emit the
expression for the condition, then compare that value to zero to get a truth
value as a 1-bit (bool) value.
Function *TheFunction = Builder.GetInsertBlock()->getParent();
// Create blocks for the then and else cases. Insert the 'then' block at the
// end of the function.
BasicBlock *ThenBB = new BasicBlock("then", TheFunction);
BasicBlock *ElseBB = new BasicBlock("else");
BasicBlock *MergeBB = new BasicBlock("ifcont");
Builder.CreateCondBr(CondV, ThenBB, ElseBB);
This code creates the basic blocks that are related to the if/then/else
statement, and correspond directly to the blocks in the example above. The
first line gets the current Function object that is being built. It
gets this by asking the builder for the current BasicBlock, and asking that
block for its "parent" (the function it is currently embedded into).
Once it has that, it creates three blocks. Note that it passes "TheFunction"
into the constructor for the "then" block. This causes the constructor to
automatically insert the new block into the end of the specified function. The
other two blocks are created, but aren't yet inserted into the function.
Once the blocks are created, we can emit the conditional branch that chooses
between them. Note that creating new blocks does not implicitly affect the
LLVMBuilder, so it is still inserting into the block that the condition
went into. Also note that it is creating a branch to the "then" block and the
"else" block, even though the "else" block isn't inserted into the function yet.
This is all ok: it is the standard way that LLVM supports forward
references.
// Emit then value.
Builder.SetInsertPoint(ThenBB);
Value *ThenV = Then->Codegen();
if (ThenV == 0) return 0;
Builder.CreateBr(MergeBB);
// Codegen of 'Then' can change the current block, update ThenBB for the PHI.
ThenBB = Builder.GetInsertBlock();
After the conditional branch is inserted, we move the builder to start
inserting into the "then" block. Strictly speaking, this call moves the
insertion point to be at the end of the specified block. However, since the
"then" block is empty, it also starts out by inserting at the beginning of the
block. :)
Once the insertion point is set, we recursively codegen the "then" expression
from the AST. To finish off the "then" block, we create an unconditional branch
to the merge block. One interesting (and very important) aspect of the LLVM IR
is that it requires all basic blocks
to be "terminated" with a control flow
instruction such as return or branch. This means that all control flow,
including fall throughs must be made explicit in the LLVM IR. If you
violate this rule, the verifier will emit an error.
The final line here is quite subtle, but is very important. The basic issue
is that when we create the Phi node in the merge block, we need to set up the
block/value pairs that indicate how the Phi will work. Importantly, the Phi
node expects to have an entry for each predecessor of the block in the CFG. Why
then, are we getting the current block when we just set it to ThenBB 5 lines
above? The problem is that the "Then" expression may actually itself change the
block that the Builder is emitting into if, for example, it contains a nested
"if/then/else" expression. Because calling Codegen recursively could
arbitrarily change the notion of the current block, we are required to get an
up-to-date value for code that will set up the Phi node.
// Emit else block.
TheFunction->getBasicBlockList().push_back(ElseBB);
Builder.SetInsertPoint(ElseBB);
Value *ElseV = Else->Codegen();
if (ElseV == 0) return 0;
Builder.CreateBr(MergeBB);
// Codegen of 'Else' can change the current block, update ElseBB for the PHI.
ElseBB = Builder.GetInsertBlock();
Code generation for the 'else' block is basically identical to codegen for
the 'then' block. The only significant difference is the first line, which adds
the 'else' block to the function. Recall previously that the 'else' block was
created, but not added to the function. Now that the 'then' and 'else' blocks
are emitted, we can finish up with the merge code:
// Emit merge block.
TheFunction->getBasicBlockList().push_back(MergeBB);
Builder.SetInsertPoint(MergeBB);
PHINode *PN = Builder.CreatePHI(Type::DoubleTy, "iftmp");
PN->addIncoming(ThenV, ThenBB);
PN->addIncoming(ElseV, ElseBB);
return PN;
}
The first two lines here are now familiar: the first adds the "merge" block
to the Function object (it was previously floating, like the else block above).
The second block changes the insertion point so that newly created code will go
into the "merge" block. Once that is done, we need to create the PHI node and
set up the block/value pairs for the PHI.
Finally, the CodeGen function returns the phi node as the value computed by
the if/then/else expression. In our example above, this returned value will
feed into the code for the top-level function, which will create the return
instruction.
Overall, we now have the ability to execute conditional code in
Kaleidoscope. With this extension, Kaleidoscope is a fairly complete language
that can calculate a wide variety of numeric functions. Next up we'll add
another useful expression that is familiar from non-functional languages...
Now that we know how to add basic control flow constructs to the language,
we have the tools to add more powerful things. Lets add something more
aggressive, a 'for' expression:
extern putchard(char)
def printstar(n)
for i = 1, i < n, 1.0 in
putchard(42); # ascii 42 = '*'
# print 100 '*' characters
printstar(100);
This expression defines a new variable ("i" in this case) which iterates from
a starting value, while the condition ("i < n" in this case) is true,
incrementing by an optional step value ("1.0" in this case). If the step value
is omitted, it defaults to 1.0. While the loop is true, it executes its
body expression. Because we don't have anything better to return, we'll just
define the loop as always returning 0.0. In the future when we have mutable
variables, it will get more useful.
As before, lets talk about the changes that we need to Kaleidoscope to
support this.
The lexer extensions are the same sort of thing as for if/then/else:
... in enum Token ...
// control
tok_if = -6, tok_then = -7, tok_else = -8,
tok_for = -9, tok_in = -10
... in gettok ...
if (IdentifierStr == "def") return tok_def;
if (IdentifierStr == "extern") return tok_extern;
if (IdentifierStr == "if") return tok_if;
if (IdentifierStr == "then") return tok_then;
if (IdentifierStr == "else") return tok_else;
if (IdentifierStr == "for") return tok_for;
if (IdentifierStr == "in") return tok_in;
return tok_identifier;
The AST node is just as simple. It basically boils down to capturing
the variable name and the constituent expressions in the node.
/// ForExprAST - Expression class for for/in.
class ForExprAST : public ExprAST {
std::string VarName;
ExprAST *Start, *End, *Step, *Body;
public:
ForExprAST(const std::string &varname, ExprAST *start, ExprAST *end,
ExprAST *step, ExprAST *body)
: VarName(varname), Start(start), End(end), Step(step), Body(body) {}
virtual Value *Codegen();
};
The parser code is also fairly standard. The only interesting thing here is
handling of the optional step value. The parser code handles it by checking to
see if the second comma is present. If not, it sets the step value to null in
the AST node:
/// forexpr ::= 'for' identifier '=' expr ',' expr (',' expr)? 'in' expression
static ExprAST *ParseForExpr() {
getNextToken(); // eat the for.
if (CurTok != tok_identifier)
return Error("expected identifier after for");
std::string IdName = IdentifierStr;
getNextToken(); // eat identifier.
if (CurTok != '=')
return Error("expected '=' after for");
getNextToken(); // eat '='.
ExprAST *Start = ParseExpression();
if (Start == 0) return 0;
if (CurTok != ',')
return Error("expected ',' after for start value");
getNextToken();
ExprAST *End = ParseExpression();
if (End == 0) return 0;
// The step value is optional.
ExprAST *Step = 0;
if (CurTok == ',') {
getNextToken();
Step = ParseExpression();
if (Step == 0) return 0;
}
if (CurTok != tok_in)
return Error("expected 'in' after for");
getNextToken(); // eat 'in'.
ExprAST *Body = ParseExpression();
if (Body == 0) return 0;
return new ForExprAST(IdName, Start, End, Step, Body);
}
Now we get to the good part: the LLVM IR we want to generate for this thing.
With the simple example above, we get this LLVM IR (note that this dump is
generated with optimizations disabled for clarity):
declare double @putchard(double)
define double @printstar(double %n) {
entry:
; initial value = 1.0 (inlined into phi)
br label %loop
loop: ; preds = %loop, %entry
%i = phi double [ 1.000000e+00, %entry ], [ %nextvar, %loop ]
; body
%calltmp = call double @putchard( double 4.200000e+01 )
; increment
%nextvar = add double %i, 1.000000e+00
; termination test
%cmptmp = fcmp ult double %i, %n
%booltmp = uitofp i1 %cmptmp to double
%loopcond = fcmp one double %booltmp, 0.000000e+00
br i1 %loopcond, label %loop, label %afterloop
afterloop: ; preds = %loop
; loop always returns 0.0
ret double 0.000000e+00
}
This loop contains all the same constructs we saw before: a phi node, several
expressions, and some basic blocks. Lets see how this fits together.
The first part of Codegen is very simple: we just output the start expression
for the loop value:
Value *ForExprAST::Codegen() {
// Emit the start code first, without 'variable' in scope.
Value *StartVal = Start->Codegen();
if (StartVal == 0) return 0;
With this out of the way, the next step is to set up the LLVM basic block
for the start of the loop body. In the case above, the whole loop body is one
block, but remember that the body code itself could consist of multiple blocks
(e.g. if it contains an if/then/else or a for/in expression).
// Make the new basic block for the loop header, inserting after current
// block.
Function *TheFunction = Builder.GetInsertBlock()->getParent();
BasicBlock *PreheaderBB = Builder.GetInsertBlock();
BasicBlock *LoopBB = new BasicBlock("loop", TheFunction);
// Insert an explicit fall through from the current block to the LoopBB.
Builder.CreateBr(LoopBB);
This code is similar to what we saw for if/then/else. Because we will need
it to create the Phi node, we remember the block that falls through into the
loop. Once we have that, we create the actual block that starts the loop and
create an unconditional branch for the fall-through between the two blocks.
// Start insertion in LoopBB.
Builder.SetInsertPoint(LoopBB);
// Start the PHI node with an entry for Start.
PHINode *Variable = Builder.CreatePHI(Type::DoubleTy, VarName.c_str());
Variable->addIncoming(StartVal, PreheaderBB);
Now that the "preheader" for the loop is set up, we switch to emitting code
for the loop body. To begin with, we move the insertion point and create the
PHI node for the loop induction variable. Since we already know the incoming
value for the starting value, we add it to the Phi node. Note that the Phi will
eventually get a second value for the backedge, but we can't set it up yet
(because it doesn't exist!).
// Within the loop, the variable is defined equal to the PHI node. If it
// shadows an existing variable, we have to restore it, so save it now.
Value *OldVal = NamedValues[VarName];
NamedValues[VarName] = Variable;
// Emit the body of the loop. This, like any other expr, can change the
// current BB. Note that we ignore the value computed by the body, but don't
// allow an error.
if (Body->Codegen() == 0)
return 0;
Now the code starts to get more interesting. Our 'for' loop introduces a new
variable to the symbol table. This means that our symbol table can now contain
either function arguments or loop variables. To handle this, before we codegen
the body of the loop, we add the loop variable as the current value for its
name. Note that it is possible that there is a variable of the same name in the
outer scope. It would be easy to make this an error (emit an error and return
null if there is already an entry for VarName) but we choose to allow shadowing
of variables. In order to handle this correctly, we remember the Value that
we are potentially shadowing in OldVal (which will be null if there is
no shadowed variable).
Once the loop variable is set into the symbol table, the code recursively
codegen's the body. This allows the body to use the loop variable: any
references to it will naturally find it in the symbol table.
// Emit the step value.
Value *StepVal;
if (Step) {
StepVal = Step->Codegen();
if (StepVal == 0) return 0;
} else {
// If not specified, use 1.0.
StepVal = ConstantFP::get(Type::DoubleTy, APFloat(1.0));
}
Value *NextVar = Builder.CreateAdd(Variable, StepVal, "nextvar");
Now that the body is emitted, we compute the next value of the iteration
variable by adding the step value, or 1.0 if it isn't present. 'NextVar'
will be the value of the loop variable on the next iteration of the loop.
// Compute the end condition.
Value *EndCond = End->Codegen();
if (EndCond == 0) return EndCond;
// Convert condition to a bool by comparing equal to 0.0.
EndCond = Builder.CreateFCmpONE(EndCond,
ConstantFP::get(Type::DoubleTy, APFloat(0.0)),
"loopcond");
Finally, we evaluate the exit value of the loop, to determine whether the
loop should exit. This mirrors the condition evaluation for the if/then/else
statement.
// Create the "after loop" block and insert it.
BasicBlock *LoopEndBB = Builder.GetInsertBlock();
BasicBlock *AfterBB = new BasicBlock("afterloop", TheFunction);
// Insert the conditional branch into the end of LoopEndBB.
Builder.CreateCondBr(EndCond, LoopBB, AfterBB);
// Any new code will be inserted in AfterBB.
Builder.SetInsertPoint(AfterBB);
With the code for the body of the loop complete, we just need to finish up
the control flow for it. This code remembers the end block (for the phi node), then creates the block for the loop exit ("afterloop"). Based on the value of the
exit condition, it creates a conditional branch that chooses between executing
the loop again and exiting the loop. Any future code is emitted in the
"afterloop" block, so it sets the insertion position to it.
// Add a new entry to the PHI node for the backedge.
Variable->addIncoming(NextVar, LoopEndBB);
// Restore the unshadowed variable.
if (OldVal)
NamedValues[VarName] = OldVal;
else
NamedValues.erase(VarName);
// for expr always returns 0.0.
return Constant::getNullValue(Type::DoubleTy);
}
The final code handles various cleanups: now that we have the "NextVar"
value, we can add the incoming value to the loop PHI node. After that, we
remove the loop variable from the symbol table, so that it isn't in scope after
the for loop. Finally, code generation of the for loop always returns 0.0, so
that is what we return from ForExprAST::Codegen.
With this, we conclude the "adding control flow to Kaleidoscope" chapter of
the tutorial. In this chapter we added two control flow constructs, and used them to motivate a couple of aspects of the LLVM IR that are important for front-end implementors
to know. In the next chapter of our saga, we will get a bit crazier and add
user-defined operators to our poor innocent
language.
Here is the complete code listing for our running example, enhanced with the
if/then/else and for expressions.. To build this example, use:
# Compile
g++ -g toy.cpp `llvm-config --cppflags --ldflags --libs core jit native` -O3 -o toy
# Run
./toy
Here is the code:
#include "llvm/DerivedTypes.h"
#include "llvm/ExecutionEngine/ExecutionEngine.h"
#include "llvm/Module.h"
#include "llvm/ModuleProvider.h"
#include "llvm/PassManager.h"
#include "llvm/Analysis/Verifier.h"
#include "llvm/Target/TargetData.h"
#include "llvm/Transforms/Scalar.h"
#include "llvm/Support/LLVMBuilder.h"
#include <cstdio>
#include <string>
#include <map>
#include <vector>
using namespace llvm;
//===----------------------------------------------------------------------===//
// Lexer
//===----------------------------------------------------------------------===//
// The lexer returns tokens [0-255] if it is an unknown character, otherwise one
// of these for known things.
enum Token {
tok_eof = -1,
// commands
tok_def = -2, tok_extern = -3,
// primary
tok_identifier = -4, tok_number = -5,
// control
tok_if = -6, tok_then = -7, tok_else = -8,
tok_for = -9, tok_in = -10
};
static std::string IdentifierStr; // Filled in if tok_identifier
static double NumVal; // Filled in if tok_number
/// gettok - Return the next token from standard input.
static int gettok() {
static int LastChar = ' ';
// Skip any whitespace.
while (isspace(LastChar))
LastChar = getchar();
if (isalpha(LastChar)) { // identifier: [a-zA-Z][a-zA-Z0-9]*
IdentifierStr = LastChar;
while (isalnum((LastChar = getchar())))
IdentifierStr += LastChar;
if (IdentifierStr == "def") return tok_def;
if (IdentifierStr == "extern") return tok_extern;
if (IdentifierStr == "if") return tok_if;
if (IdentifierStr == "then") return tok_then;
if (IdentifierStr == "else") return tok_else;
if (IdentifierStr == "for") return tok_for;
if (IdentifierStr == "in") return tok_in;
return tok_identifier;
}
if (isdigit(LastChar) || LastChar == '.') { // Number: [0-9.]+
std::string NumStr;
do {
NumStr += LastChar;
LastChar = getchar();
} while (isdigit(LastChar) || LastChar == '.');
NumVal = strtod(NumStr.c_str(), 0);
return tok_number;
}
if (LastChar == '#') {
// Comment until end of line.
do LastChar = getchar();
while (LastChar != EOF && LastChar != '\n' && LastChar != '\r');
if (LastChar != EOF)
return gettok();
}
// Check for end of file. Don't eat the EOF.
if (LastChar == EOF)
return tok_eof;
// Otherwise, just return the character as its ascii value.
int ThisChar = LastChar;
LastChar = getchar();
return ThisChar;
}
//===----------------------------------------------------------------------===//
// Abstract Syntax Tree (aka Parse Tree)
//===----------------------------------------------------------------------===//
/// ExprAST - Base class for all expression nodes.
class ExprAST {
public:
virtual ~ExprAST() {}
virtual Value *Codegen() = 0;
};
/// NumberExprAST - Expression class for numeric literals like "1.0".
class NumberExprAST : public ExprAST {
double Val;
public:
NumberExprAST(double val) : Val(val) {}
virtual Value *Codegen();
};
/// VariableExprAST - Expression class for referencing a variable, like "a".
class VariableExprAST : public ExprAST {
std::string Name;
public:
VariableExprAST(const std::string &name) : Name(name) {}
virtual Value *Codegen();
};
/// BinaryExprAST - Expression class for a binary operator.
class BinaryExprAST : public ExprAST {
char Op;
ExprAST *LHS, *RHS;
public:
BinaryExprAST(char op, ExprAST *lhs, ExprAST *rhs)
: Op(op), LHS(lhs), RHS(rhs) {}
virtual Value *Codegen();
};
/// CallExprAST - Expression class for function calls.
class CallExprAST : public ExprAST {
std::string Callee;
std::vector<ExprAST*> Args;
public:
CallExprAST(const std::string &callee, std::vector<ExprAST*> &args)
: Callee(callee), Args(args) {}
virtual Value *Codegen();
};
/// IfExprAST - Expression class for if/then/else.
class IfExprAST : public ExprAST {
ExprAST *Cond, *Then, *Else;
public:
IfExprAST(ExprAST *cond, ExprAST *then, ExprAST *_else)
: Cond(cond), Then(then), Else(_else) {}
virtual Value *Codegen();
};
/// ForExprAST - Expression class for for/in.
class ForExprAST : public ExprAST {
std::string VarName;
ExprAST *Start, *End, *Step, *Body;
public:
ForExprAST(const std::string &varname, ExprAST *start, ExprAST *end,
ExprAST *step, ExprAST *body)
: VarName(varname), Start(start), End(end), Step(step), Body(body) {}
virtual Value *Codegen();
};
/// PrototypeAST - This class represents the "prototype" for a function,
/// which captures its argument names as well as if it is an operator.
class PrototypeAST {
std::string Name;
std::vector<std::string> Args;
public:
PrototypeAST(const std::string &name, const std::vector<std::string> &args)
: Name(name), Args(args) {}
Function *Codegen();
};
/// FunctionAST - This class represents a function definition itself.
class FunctionAST {
PrototypeAST *Proto;
ExprAST *Body;
public:
FunctionAST(PrototypeAST *proto, ExprAST *body)
: Proto(proto), Body(body) {}
Function *Codegen();
};
//===----------------------------------------------------------------------===//
// Parser
//===----------------------------------------------------------------------===//
/// CurTok/getNextToken - Provide a simple token buffer. CurTok is the current
/// token the parser it looking at. getNextToken reads another token from the
/// lexer and updates CurTok with its results.
static int CurTok;
static int getNextToken() {
return CurTok = gettok();
}
/// BinopPrecedence - This holds the precedence for each binary operator that is
/// defined.
static std::map<char, int> BinopPrecedence;
/// GetTokPrecedence - Get the precedence of the pending binary operator token.
static int GetTokPrecedence() {
if (!isascii(CurTok))
return -1;
// Make sure it's a declared binop.
int TokPrec = BinopPrecedence[CurTok];
if (TokPrec <= 0) return -1;
return TokPrec;
}
/// Error* - These are little helper functions for error handling.
ExprAST *Error(const char *Str) { fprintf(stderr, "Error: %s\n", Str);return 0;}
PrototypeAST *ErrorP(const char *Str) { Error(Str); return 0; }
FunctionAST *ErrorF(const char *Str) { Error(Str); return 0; }
static ExprAST *ParseExpression();
/// identifierexpr
/// ::= identifier
/// ::= identifier '(' expression* ')'
static ExprAST *ParseIdentifierExpr() {
std::string IdName = IdentifierStr;
getNextToken(); // eat identifier.
if (CurTok != '(') // Simple variable ref.
return new VariableExprAST(IdName);
// Call.
getNextToken(); // eat (
std::vector<ExprAST*> Args;
if (CurTok != ')') {
while (1) {
ExprAST *Arg = ParseExpression();
if (!Arg) return 0;
Args.push_back(Arg);
if (CurTok == ')') break;
if (CurTok != ',')
return Error("Expected ')'");
getNextToken();
}
}
// Eat the ')'.
getNextToken();
return new CallExprAST(IdName, Args);
}
/// numberexpr ::= number
static ExprAST *ParseNumberExpr() {
ExprAST *Result = new NumberExprAST(NumVal);
getNextToken(); // consume the number
return Result;
}
/// parenexpr ::= '(' expression ')'
static ExprAST *ParseParenExpr() {
getNextToken(); // eat (.
ExprAST *V = ParseExpression();
if (!V) return 0;
if (CurTok != ')')
return Error("expected ')'");
getNextToken(); // eat ).
return V;
}
/// ifexpr ::= 'if' expression 'then' expression 'else' expression
static ExprAST *ParseIfExpr() {
getNextToken(); // eat the if.
// condition.
ExprAST *Cond = ParseExpression();
if (!Cond) return 0;
if (CurTok != tok_then)
return Error("expected then");
getNextToken(); // eat the then
ExprAST *Then = ParseExpression();
if (Then == 0) return 0;
if (CurTok != tok_else)
return Error("expected else");
getNextToken();
ExprAST *Else = ParseExpression();
if (!Else) return 0;
return new IfExprAST(Cond, Then, Else);
}
/// forexpr ::= 'for' identifier '=' expr ',' expr (',' expr)? 'in' expression
static ExprAST *ParseForExpr() {
getNextToken(); // eat the for.
if (CurTok != tok_identifier)
return Error("expected identifier after for");
std::string IdName = IdentifierStr;
getNextToken(); // eat identifier.
if (CurTok != '=')
return Error("expected '=' after for");
getNextToken(); // eat '='.
ExprAST *Start = ParseExpression();
if (Start == 0) return 0;
if (CurTok != ',')
return Error("expected ',' after for start value");
getNextToken();
ExprAST *End = ParseExpression();
if (End == 0) return 0;
// The step value is optional.
ExprAST *Step = 0;
if (CurTok == ',') {
getNextToken();
Step = ParseExpression();
if (Step == 0) return 0;
}
if (CurTok != tok_in)
return Error("expected 'in' after for");
getNextToken(); // eat 'in'.
ExprAST *Body = ParseExpression();
if (Body == 0) return 0;
return new ForExprAST(IdName, Start, End, Step, Body);
}
/// primary
/// ::= identifierexpr
/// ::= numberexpr
/// ::= parenexpr
/// ::= ifexpr
/// ::= forexpr
static ExprAST *ParsePrimary() {
switch (CurTok) {
default: return Error("unknown token when expecting an expression");
case tok_identifier: return ParseIdentifierExpr();
case tok_number: return ParseNumberExpr();
case '(': return ParseParenExpr();
case tok_if: return ParseIfExpr();
case tok_for: return ParseForExpr();
}
}
/// binoprhs
/// ::= ('+' primary)*
static ExprAST *ParseBinOpRHS(int ExprPrec, ExprAST *LHS) {
// If this is a binop, find its precedence.
while (1) {
int TokPrec = GetTokPrecedence();
// If this is a binop that binds at least as tightly as the current binop,
// consume it, otherwise we are done.
if (TokPrec < ExprPrec)
return LHS;
// Okay, we know this is a binop.
int BinOp = CurTok;
getNextToken(); // eat binop
// Parse the primary expression after the binary operator.
ExprAST *RHS = ParsePrimary();
if (!RHS) return 0;
// If BinOp binds less tightly with RHS than the operator after RHS, let
// the pending operator take RHS as its LHS.
int NextPrec = GetTokPrecedence();
if (TokPrec < NextPrec) {
RHS = ParseBinOpRHS(TokPrec+1, RHS);
if (RHS == 0) return 0;
}
// Merge LHS/RHS.
LHS = new BinaryExprAST(BinOp, LHS, RHS);
}
}
/// expression
/// ::= primary binoprhs
///
static ExprAST *ParseExpression() {
ExprAST *LHS = ParsePrimary();
if (!LHS) return 0;
return ParseBinOpRHS(0, LHS);
}
/// prototype
/// ::= id '(' id* ')'
static PrototypeAST *ParsePrototype() {
if (CurTok != tok_identifier)
return ErrorP("Expected function name in prototype");
std::string FnName = IdentifierStr;
getNextToken();
if (CurTok != '(')
return ErrorP("Expected '(' in prototype");
std::vector<std::string> ArgNames;
while (getNextToken() == tok_identifier)
ArgNames.push_back(IdentifierStr);
if (CurTok != ')')
return ErrorP("Expected ')' in prototype");
// success.
getNextToken(); // eat ')'.
return new PrototypeAST(FnName, ArgNames);
}
/// definition ::= 'def' prototype expression
static FunctionAST *ParseDefinition() {
getNextToken(); // eat def.
PrototypeAST *Proto = ParsePrototype();
if (Proto == 0) return 0;
if (ExprAST *E = ParseExpression())
return new FunctionAST(Proto, E);
return 0;
}
/// toplevelexpr ::= expression
static FunctionAST *ParseTopLevelExpr() {
if (ExprAST *E = ParseExpression()) {
// Make an anonymous proto.
PrototypeAST *Proto = new PrototypeAST("", std::vector<std::string>());
return new FunctionAST(Proto, E);
}
return 0;
}
/// external ::= 'extern' prototype
static PrototypeAST *ParseExtern() {
getNextToken(); // eat extern.
return ParsePrototype();
}
//===----------------------------------------------------------------------===//
// Code Generation
//===----------------------------------------------------------------------===//
static Module *TheModule;
static LLVMFoldingBuilder Builder;
static std::map<std::string, Value*> NamedValues;
static FunctionPassManager *TheFPM;
Value *ErrorV(const char *Str) { Error(Str); return 0; }
Value *NumberExprAST::Codegen() {
return ConstantFP::get(Type::DoubleTy, APFloat(Val));
}
Value *VariableExprAST::Codegen() {
// Look this variable up in the function.
Value *V = NamedValues[Name];
return V ? V : ErrorV("Unknown variable name");
}
Value *BinaryExprAST::Codegen() {
Value *L = LHS->Codegen();
Value *R = RHS->Codegen();
if (L == 0 || R == 0) return 0;
switch (Op) {
case '+': return Builder.CreateAdd(L, R, "addtmp");
case '-': return Builder.CreateSub(L, R, "subtmp");
case '*': return Builder.CreateMul(L, R, "multmp");
case '<':
L = Builder.CreateFCmpULT(L, R, "cmptmp");
// Convert bool 0/1 to double 0.0 or 1.0
return Builder.CreateUIToFP(L, Type::DoubleTy, "booltmp");
default: return ErrorV("invalid binary operator");
}
}
Value *CallExprAST::Codegen() {
// Look up the name in the global module table.
Function *CalleeF = TheModule->getFunction(Callee);
if (CalleeF == 0)
return ErrorV("Unknown function referenced");
// If argument mismatch error.
if (CalleeF->arg_size() != Args.size())
return ErrorV("Incorrect # arguments passed");
std::vector<Value*> ArgsV;
for (unsigned i = 0, e = Args.size(); i != e; ++i) {
ArgsV.push_back(Args[i]->Codegen());
if (ArgsV.back() == 0) return 0;
}
return Builder.CreateCall(CalleeF, ArgsV.begin(), ArgsV.end(), "calltmp");
}
Value *IfExprAST::Codegen() {
Value *CondV = Cond->Codegen();
if (CondV == 0) return 0;
// Convert condition to a bool by comparing equal to 0.0.
CondV = Builder.CreateFCmpONE(CondV,
ConstantFP::get(Type::DoubleTy, APFloat(0.0)),
"ifcond");
Function *TheFunction = Builder.GetInsertBlock()->getParent();
// Create blocks for the then and else cases. Insert the 'then' block at the
// end of the function.
BasicBlock *ThenBB = new BasicBlock("then", TheFunction);
BasicBlock *ElseBB = new BasicBlock("else");
BasicBlock *MergeBB = new BasicBlock("ifcont");
Builder.CreateCondBr(CondV, ThenBB, ElseBB);
// Emit then value.
Builder.SetInsertPoint(ThenBB);
Value *ThenV = Then->Codegen();
if (ThenV == 0) return 0;
Builder.CreateBr(MergeBB);
// Codegen of 'Then' can change the current block, update ThenBB for the PHI.
ThenBB = Builder.GetInsertBlock();
// Emit else block.
TheFunction->getBasicBlockList().push_back(ElseBB);
Builder.SetInsertPoint(ElseBB);
Value *ElseV = Else->Codegen();
if (ElseV == 0) return 0;
Builder.CreateBr(MergeBB);
// Codegen of 'Else' can change the current block, update ElseBB for the PHI.
ElseBB = Builder.GetInsertBlock();
// Emit merge block.
TheFunction->getBasicBlockList().push_back(MergeBB);
Builder.SetInsertPoint(MergeBB);
PHINode *PN = Builder.CreatePHI(Type::DoubleTy, "iftmp");
PN->addIncoming(ThenV, ThenBB);
PN->addIncoming(ElseV, ElseBB);
return PN;
}
Value *ForExprAST::Codegen() {
// Output this as:
// ...
// start = startexpr
// goto loop
// loop:
// variable = phi [start, loopheader], [nextvariable, loopend]
// ...
// bodyexpr
// ...
// loopend:
// step = stepexpr
// nextvariable = variable + step
// endcond = endexpr
// br endcond, loop, endloop
// outloop:
// Emit the start code first, without 'variable' in scope.
Value *StartVal = Start->Codegen();
if (StartVal == 0) return 0;
// Make the new basic block for the loop header, inserting after current
// block.
Function *TheFunction = Builder.GetInsertBlock()->getParent();
BasicBlock *PreheaderBB = Builder.GetInsertBlock();
BasicBlock *LoopBB = new BasicBlock("loop", TheFunction);
// Insert an explicit fall through from the current block to the LoopBB.
Builder.CreateBr(LoopBB);
// Start insertion in LoopBB.
Builder.SetInsertPoint(LoopBB);
// Start the PHI node with an entry for Start.
PHINode *Variable = Builder.CreatePHI(Type::DoubleTy, VarName.c_str());
Variable->addIncoming(StartVal, PreheaderBB);
// Within the loop, the variable is defined equal to the PHI node. If it
// shadows an existing variable, we have to restore it, so save it now.
Value *OldVal = NamedValues[VarName];
NamedValues[VarName] = Variable;
// Emit the body of the loop. This, like any other expr, can change the
// current BB. Note that we ignore the value computed by the body, but don't
// allow an error.
if (Body->Codegen() == 0)
return 0;
// Emit the step value.
Value *StepVal;
if (Step) {
StepVal = Step->Codegen();
if (StepVal == 0) return 0;
} else {
// If not specified, use 1.0.
StepVal = ConstantFP::get(Type::DoubleTy, APFloat(1.0));
}
Value *NextVar = Builder.CreateAdd(Variable, StepVal, "nextvar");
// Compute the end condition.
Value *EndCond = End->Codegen();
if (EndCond == 0) return EndCond;
// Convert condition to a bool by comparing equal to 0.0.
EndCond = Builder.CreateFCmpONE(EndCond,
ConstantFP::get(Type::DoubleTy, APFloat(0.0)),
"loopcond");
// Create the "after loop" block and insert it.
BasicBlock *LoopEndBB = Builder.GetInsertBlock();
BasicBlock *AfterBB = new BasicBlock("afterloop", TheFunction);
// Insert the conditional branch into the end of LoopEndBB.
Builder.CreateCondBr(EndCond, LoopBB, AfterBB);
// Any new code will be inserted in AfterBB.
Builder.SetInsertPoint(AfterBB);
// Add a new entry to the PHI node for the backedge.
Variable->addIncoming(NextVar, LoopEndBB);
// Restore the unshadowed variable.
if (OldVal)
NamedValues[VarName] = OldVal;
else
NamedValues.erase(VarName);
// for expr always returns 0.0.
return Constant::getNullValue(Type::DoubleTy);
}
Function *PrototypeAST::Codegen() {
// Make the function type: double(double,double) etc.
std::vector<const Type*> Doubles(Args.size(), Type::DoubleTy);
FunctionType *FT = FunctionType::get(Type::DoubleTy, Doubles, false);
Function *F = new Function(FT, Function::ExternalLinkage, Name, TheModule);
// If F conflicted, there was already something named 'Name'. If it has a
// body, don't allow redefinition or reextern.
if (F->getName() != Name) {
// Delete the one we just made and get the existing one.
F->eraseFromParent();
F = TheModule->getFunction(Name);
// If F already has a body, reject this.
if (!F->empty()) {
ErrorF("redefinition of function");
return 0;
}
// If F took a different number of args, reject.
if (F->arg_size() != Args.size()) {
ErrorF("redefinition of function with different # args");
return 0;
}
}
// Set names for all arguments.
unsigned Idx = 0;
for (Function::arg_iterator AI = F->arg_begin(); Idx != Args.size();
++AI, ++Idx) {
AI->setName(Args[Idx]);
// Add arguments to variable symbol table.
NamedValues[Args[Idx]] = AI;
}
return F;
}
Function *FunctionAST::Codegen() {
NamedValues.clear();
Function *TheFunction = Proto->Codegen();
if (TheFunction == 0)
return 0;
// Create a new basic block to start insertion into.
BasicBlock *BB = new BasicBlock("entry", TheFunction);
Builder.SetInsertPoint(BB);
if (Value *RetVal = Body->Codegen()) {
// Finish off the function.
Builder.CreateRet(RetVal);
// Validate the generated code, checking for consistency.
verifyFunction(*TheFunction);
// Optimize the function.
TheFPM->run(*TheFunction);
return TheFunction;
}
// Error reading body, remove function.
TheFunction->eraseFromParent();
return 0;
}
//===----------------------------------------------------------------------===//
// Top-Level parsing and JIT Driver
//===----------------------------------------------------------------------===//
static ExecutionEngine *TheExecutionEngine;
static void HandleDefinition() {
if (FunctionAST *F = ParseDefinition()) {
if (Function *LF = F->Codegen()) {
fprintf(stderr, "Read function definition:");
LF->dump();
}
} else {
// Skip token for error recovery.
getNextToken();
}
}
static void HandleExtern() {
if (PrototypeAST *P = ParseExtern()) {
if (Function *F = P->Codegen()) {
fprintf(stderr, "Read extern: ");
F->dump();
}
} else {
// Skip token for error recovery.
getNextToken();
}
}
static void HandleTopLevelExpression() {
// Evaluate a top level expression into an anonymous function.
if (FunctionAST *F = ParseTopLevelExpr()) {
if (Function *LF = F->Codegen()) {
// JIT the function, returning a function pointer.
void *FPtr = TheExecutionEngine->getPointerToFunction(LF);
// Cast it to the right type (takes no arguments, returns a double) so we
// can call it as a native function.
double (*FP)() = (double (*)())FPtr;
fprintf(stderr, "Evaluated to %f\n", FP());
}
} else {
// Skip token for error recovery.
getNextToken();
}
}
/// top ::= definition | external | expression | ';'
static void MainLoop() {
while (1) {
fprintf(stderr, "ready> ");
switch (CurTok) {
case tok_eof: return;
case ';': getNextToken(); break; // ignore top level semicolons.
case tok_def: HandleDefinition(); break;
case tok_extern: HandleExtern(); break;
default: HandleTopLevelExpression(); break;
}
}
}
//===----------------------------------------------------------------------===//
// "Library" functions that can be "extern'd" from user code.
//===----------------------------------------------------------------------===//
/// putchard - putchar that takes a double and returns 0.
extern "C"
double putchard(double X) {
putchar((char)X);
return 0;
}
//===----------------------------------------------------------------------===//
// Main driver code.
//===----------------------------------------------------------------------===//
int main() {
// Install standard binary operators.
// 1 is lowest precedence.
BinopPrecedence['<'] = 10;
BinopPrecedence['+'] = 20;
BinopPrecedence['-'] = 20;
BinopPrecedence['*'] = 40; // highest.
// Prime the first token.
fprintf(stderr, "ready> ");
getNextToken();
// Make the module, which holds all the code.
TheModule = new Module("my cool jit");
// Create the JIT.
TheExecutionEngine = ExecutionEngine::create(TheModule);
{
ExistingModuleProvider OurModuleProvider(TheModule);
FunctionPassManager OurFPM(&OurModuleProvider);
// Set up the optimizer pipeline. Start with registering info about how the
// target lays out data structures.
OurFPM.add(new TargetData(*TheExecutionEngine->getTargetData()));
// Do simple "peephole" optimizations and bit-twiddling optzns.
OurFPM.add(createInstructionCombiningPass());
// Reassociate expressions.
OurFPM.add(createReassociatePass());
// Eliminate Common SubExpressions.
OurFPM.add(createGVNPass());
// Simplify the control flow graph (deleting unreachable blocks, etc).
OurFPM.add(createCFGSimplificationPass());
// Set the global so the code gen can use this.
TheFPM = &OurFPM;
// Run the main "interpreter loop" now.
MainLoop();
TheFPM = 0;
} // Free module provider and pass manager.
// Print out all of the generated code.
TheModule->dump();
return 0;
}

 Chris Lattner
Chris Lattner
The LLVM Compiler Infrastructure
Last modified: $Date: 2007-10-17 11:05:13 -0700 (Wed, 17 Oct 2007) $