|
|
||
|---|---|---|
| asm | ||
| src | ||
| VS2017 | ||
| Xcode/lzsa.xcodeproj | ||
| .gitignore | ||
| BlockFormat_LZSA1.md | ||
| BlockFormat_LZSA2.md | ||
| LICENSE | ||
| LICENSE.cc0.md | ||
| LICENSE.zlib.md | ||
| Makefile | ||
| pareto_graph.png | ||
| README.md | ||
| StreamFormat.md | ||
{kind=link}
LZSA is a collection of byte-aligned compression formats that are specifically engineered for very fast decompression on 8-bit systems. It can compress files of any size by using blocks of a maximum size of 64 Kb with block-interdependent compression and up to 64 Kb of back-references for matches.
 *ZX Spectrum
*ZX Spectrum
Check out The Hollow by Darklite and Offense, winner of the Solskogen 2019 wild compo, that uses LZSA on Z80.
The LZSA compression tool uses an aggressive optimal packing strategy to try to find the sequence of commands that gives the smallest packed file that decompresses to the original while maintaining the maximum possible decompression speed.
The compression formats give the user choices that range from decompressing faster than LZ4 on 8-bit systems with better compression, to compressing as well as ZX7 with much better decompression speed. LZSA1 is designed to replace LZ4 and LZSA2 to replace ZX7, in 8-bit scenarios.
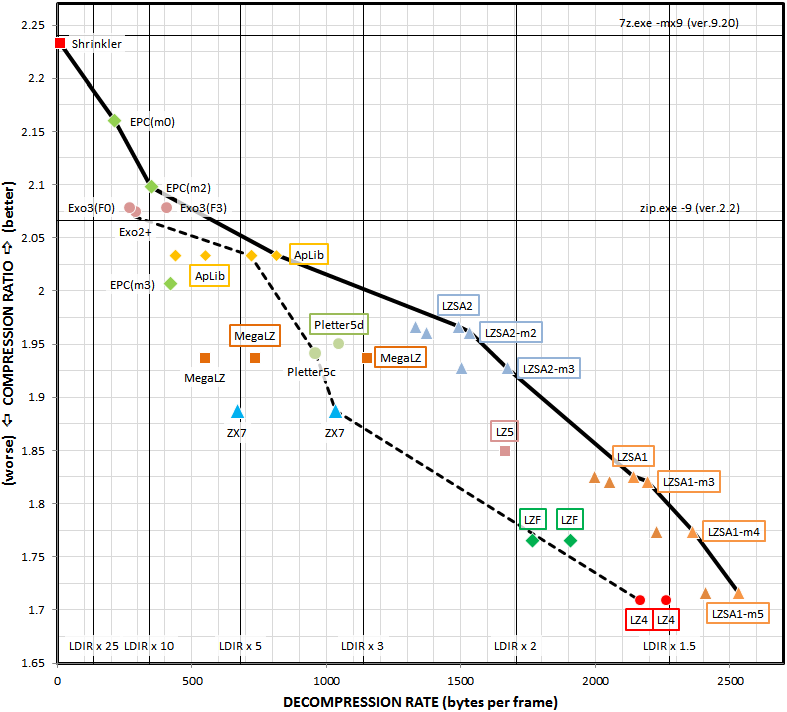
Compression ratio comparison between LZSA and other optimal packers, for a workload composed of ZX Spectrum and C64 files:
Bytes Ratio Decompression speed vs. LZ4
LZSA2 685610 53,18% <------ 75%
ZX7 687133 53,30% 47,73%
LZ5 1.4.1 727107 56,40% 75%
LZSA1 736169 57,11% <------ 90%
Lizard -29 776122 60,21% Not measured
LZ4_HC -19 -B4 -BD 781049 60,59% 100%
Uncompressed 1289127 100% N/A
Performance over well-known compression corpus files:
Uncompressed LZ4_HC -19 -B4 -BD LZSA1 LZSA2
Canterbury 2810784 935827 (33,29%) 855044 (30,42%) 789075 (28,07%)
Silesia 211938580 77299725 (36,47%) 73707039 (34,78%) 69983184 (33,02%)
Calgary 3251493 1248780 (38,40%) 1196448 (36,80%) 1125462 (34,61%)
Large 11159482 3771025 (33,79%) 3648420 (32,69%) 3528725 (31,62%)
enwik9 1000000000 371841591 (37,18%) 355360717 (35,54%) 337063553 (33,71%)
As an example of LZSA1's simplicity, a size-optimized decompressor on Z80 has been implemented in 67 bytes.
The compressor is approximately 2X slower than LZ4_HC but compresses better while maintaining similar decompression speeds and decompressor simplicity.
The main differences between LZSA1 and the LZ4 compression format are:
- The use of short (8-bit) match offsets where possible. The match-finder and optimizer cooperate to try and use the shortest match offsets possible.
- Shorter encoding of lengths. As blocks are maximum 64 Kb in size, lengths can only be up to 64 Kb.
- As a result of the smaller commands due to the possibly shorter match offsets, a minimum match size of 3 bytes instead of 4. The use of small matches is driven by the optimizer, and used where they provide gains.
As for LZSA2:
- 5-bit, 9-bit, 13-bit and 16-bit match offsets, using nibble encoding
- Shorter encoding of lengths, also using nibbles
- A minmatch of 2 bytes
- No (slow) bit-packing. LZSA2 uses byte alignment in the hot path, and nibbles.
Inspirations:
- LZ4 by Yann Collet.
- LZ5/Lizard by Przemyslaw Skibinski and Yann Collet.
- The suffix array intervals in Wimlib by Eric Biggers.
- ZX7 by Einar Saukas
License:
- The LZSA code is available under the Zlib license.
- The match finder (matchfinder.c) is available under the CC0 license due to using portions of code from Eric Bigger's Wimlib in the suffix array-based matchfinder.
8-bit assembly code:
- Z80 decompressors (size- and speed-optimized) written by introspec
- 6502 and 8088 size-optimized improvements by Peter Ferrie
- 8088 speed-optimized decompressor by Jim Leonard
Compressed format
Decompression code is provided for common 8-bit CPUs such as Z80 and 6502. However, if you would like to write your own, or understand the encoding, LZSA compresses data to a format that is fast and simple to decompress on 8-bit CPUs. It is encoded in either a stream of blocks, or as a single raw block, depending on command-line settings. The encoding is deliberately designed to avoid complicated operations on 8-bits (such as 16-bit math).